
About
Starting in Fall 2025, I will be a professor at The University of Utah in the Kahlert School of Computing. I am currently a Research Scientist at DeepMind. Previously, I was a PhD student at Carnegie Mellon University's Machine Learning Department advised by Abhinav Gupta. During my PhD, I was funded by the NDSEG and the NSF GRFP.
My research is in the intersection of CV, NLP and RL. I am particularly interested in multimodal agents (on the web, in simulation and even irl), evaluation of AI systems and dataset creation, and incorporating semantic knowledge into end-to-end learning systems. You can learn more about my research on my research page.
I completed my undergraduate education at Georgia Tech with a major in Computer Engineering and a minor in Computer Science.
How to Join my Group
I am actively looking for ambitious graduate students to join my group. The best (and only) way to do this is to apply to one of the graduate programs at Utah's Kahlert School of Computing. Be sure to mention your interest in working with me in your application. I am looking for students with:- Motivation to pursue new research directions
- Strong programming skills
- Strong research skills
- Background in Machine Learning
Happy to discuss research interests and topics with prospective students. If you want to set up a quick meeting to chat, please sign up here:
News
- August 2024: Excited to announce my upcoming role as a professor at the University of Utah, starting Fall 2025!
- June 2023: Our paper "Distilling Internet-Scale Vision-Language Models into Embodied Agents" accepted to ICML 2023.
- December 2022: Presented our work on "Learning to Navigate Wikipedia by Taking Random Walks" at NeurIPS 2022.
- October 2022: Our paper "A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge" published at ECCV 2022.
Research
My research is in the intersection of CV, NLP and RL. I am particularly interested in multimodal agents (on the web, in simulation and even irl), evaluation of AI systems and dataset creation, and incorporating semantic knowledge into end-to-end learning systems.
Publications
Please see Google Scholar for most up to date list
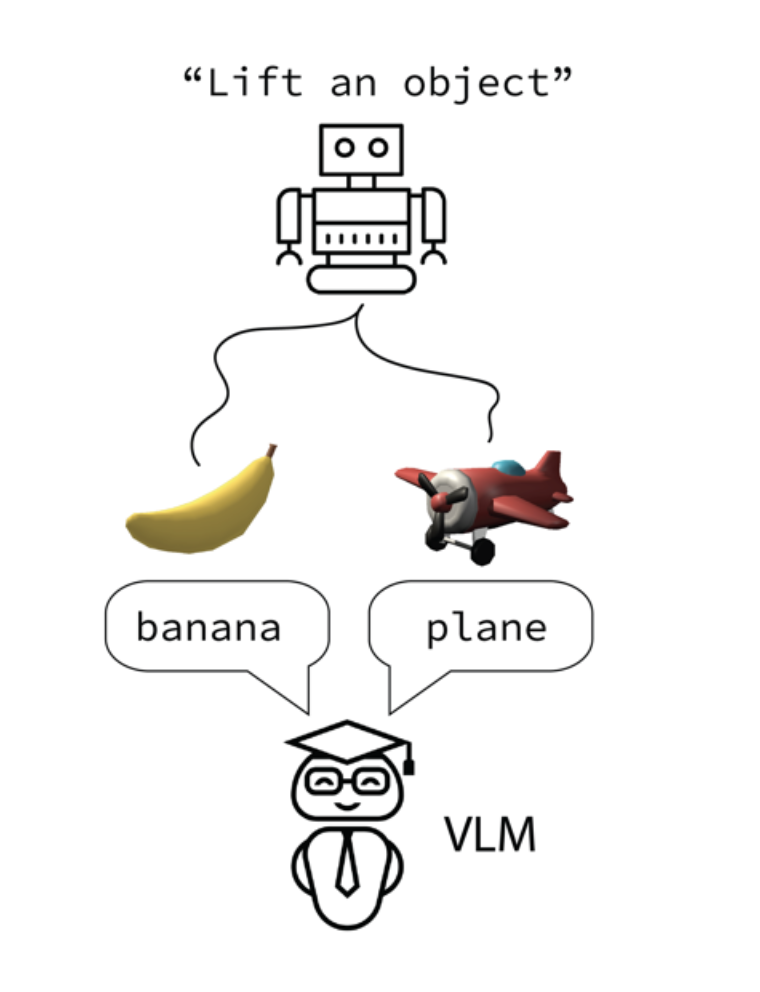
Distilling Internet-Scale Vision-Language Models into Embodied Agents.
Theodore Sumers, Kenneth Marino, Arun Ahuja, Rob Fergus, Ishita Dasgupta
ICML 2023
We propose using pretrained VLMs to supervise embodied agents by combining ideas from model distillation and hindsight experience replay (HER), using a VLM to retroactively generate language describing the agent's behavior.
[Paper]
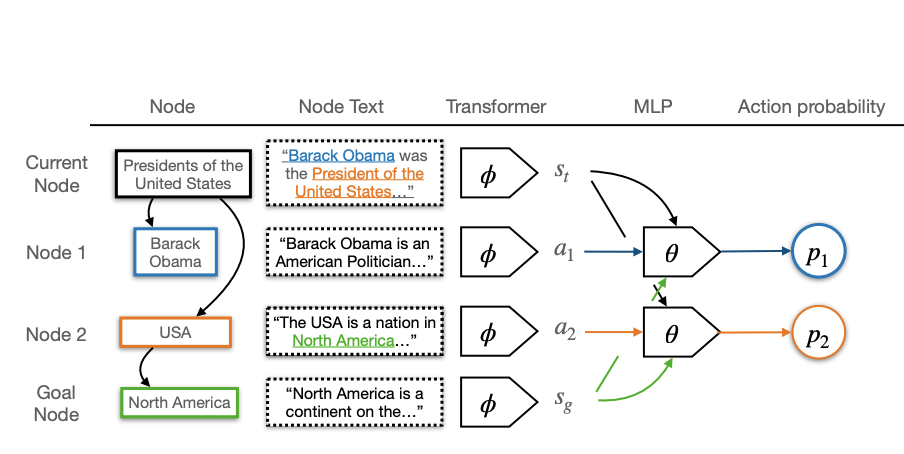
Learning to Navigate Wikipedia by Taking Random Walks.
Manzil Zaheer*, Kenneth Marino*, Will Grathwohl*, John Schultz*, Wendy Shang, Sheila Babayan, Arun Ahuja, Ishita Dasgupta, Christine Kaeser-Chen, Rob Fergus
NeurIPS 2022
We demonstrate Wikipedia link navigation using behavioral cloning of randomly sampled trajectories. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges.
[Paper]
A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge.
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, Roozbeh Mottaghi
ECCV 2022
A-OKVQA is a crowdsourced dataset composed of a diverse set of about 25K questions requiring a broad base of commonsense and world knowledge to answer.
[Paper]
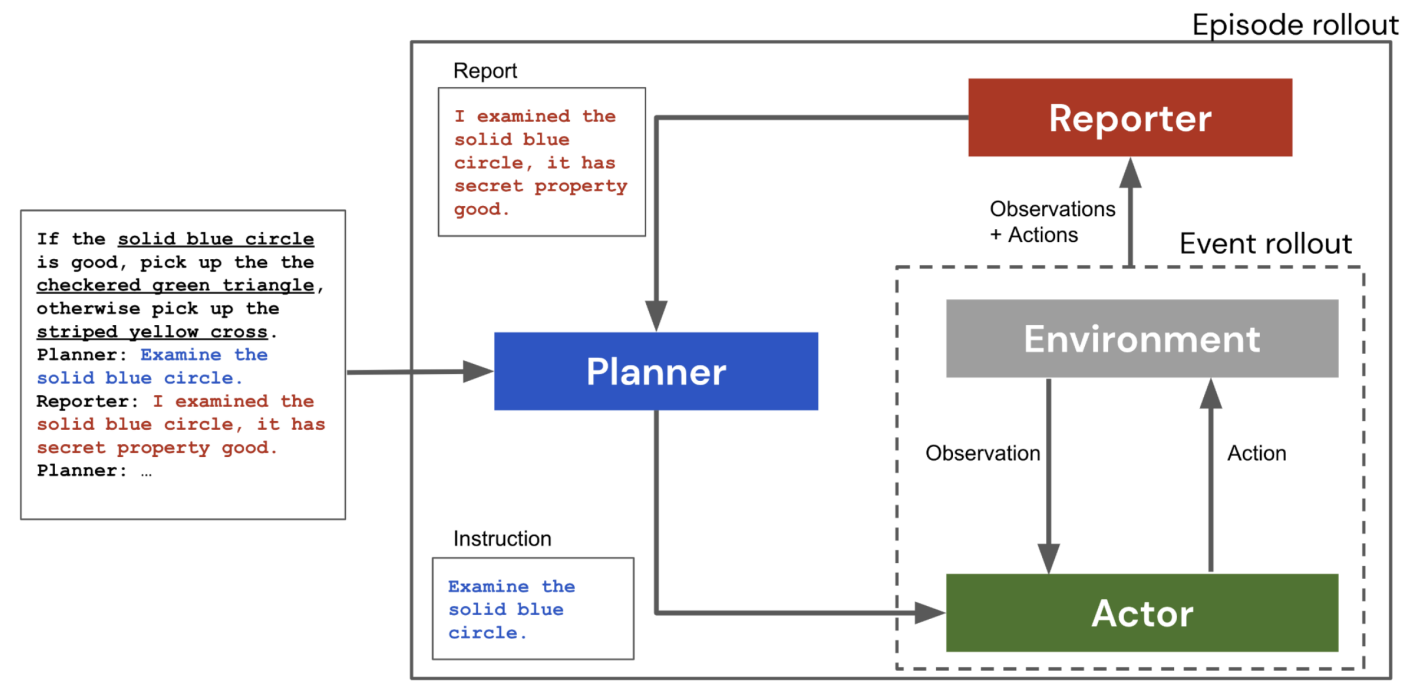
Collaborating with language models for embodied reasoning.
Ishita Dasgupta, Christine Kaeser-Chen, Kenneth Marino, Sheila Babayan, Arun Ahuja, Felix Hill, Rob Fergus
LaReL: Language and Reinforcement Learning Workshop, NeurIPS 2022
We investigate how to combine the abilities of LLMs in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command.
[Paper]
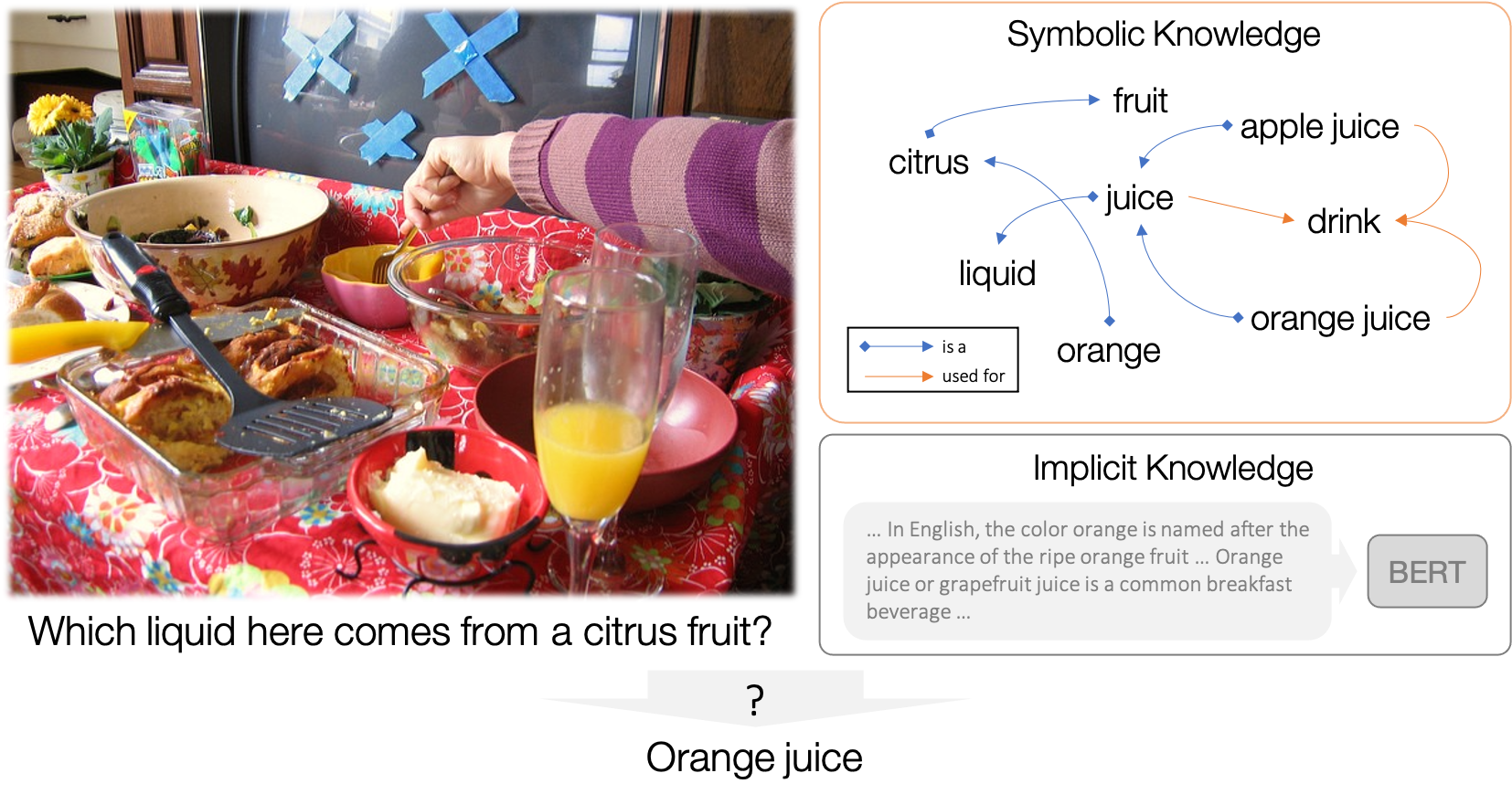
KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA.
Kenneth Marino, Xinlei Chen, Devi Parikh, Abhinav Gupta, Marcus Rohrbach
CVPR 2021
KRISP is a state-of-the-art method for knowledge based VQA on OK-VQA utilizing implicit and symbolic knowledge.
[Paper]
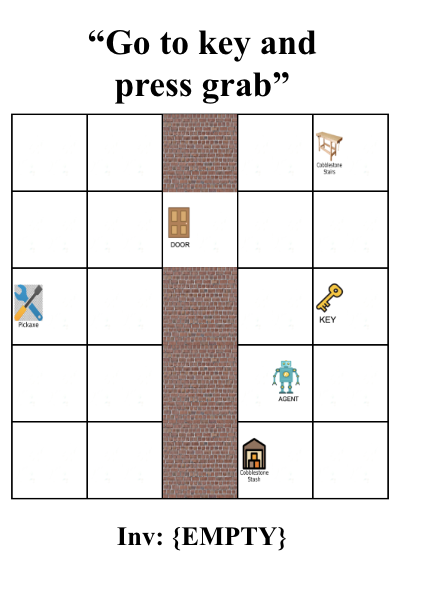
Ask Your Humans: Using Human Instructions to Improve Generalization in Reinforcement Learning.
Valerie Chen, Abhinav Gupta, Kenneth Marino
ICLR 2021
Ask Your Humans is a dataset and experimental paper looking at how we can use human-generated instructions to create interpretable and adaptable RL agents.
[Paper]
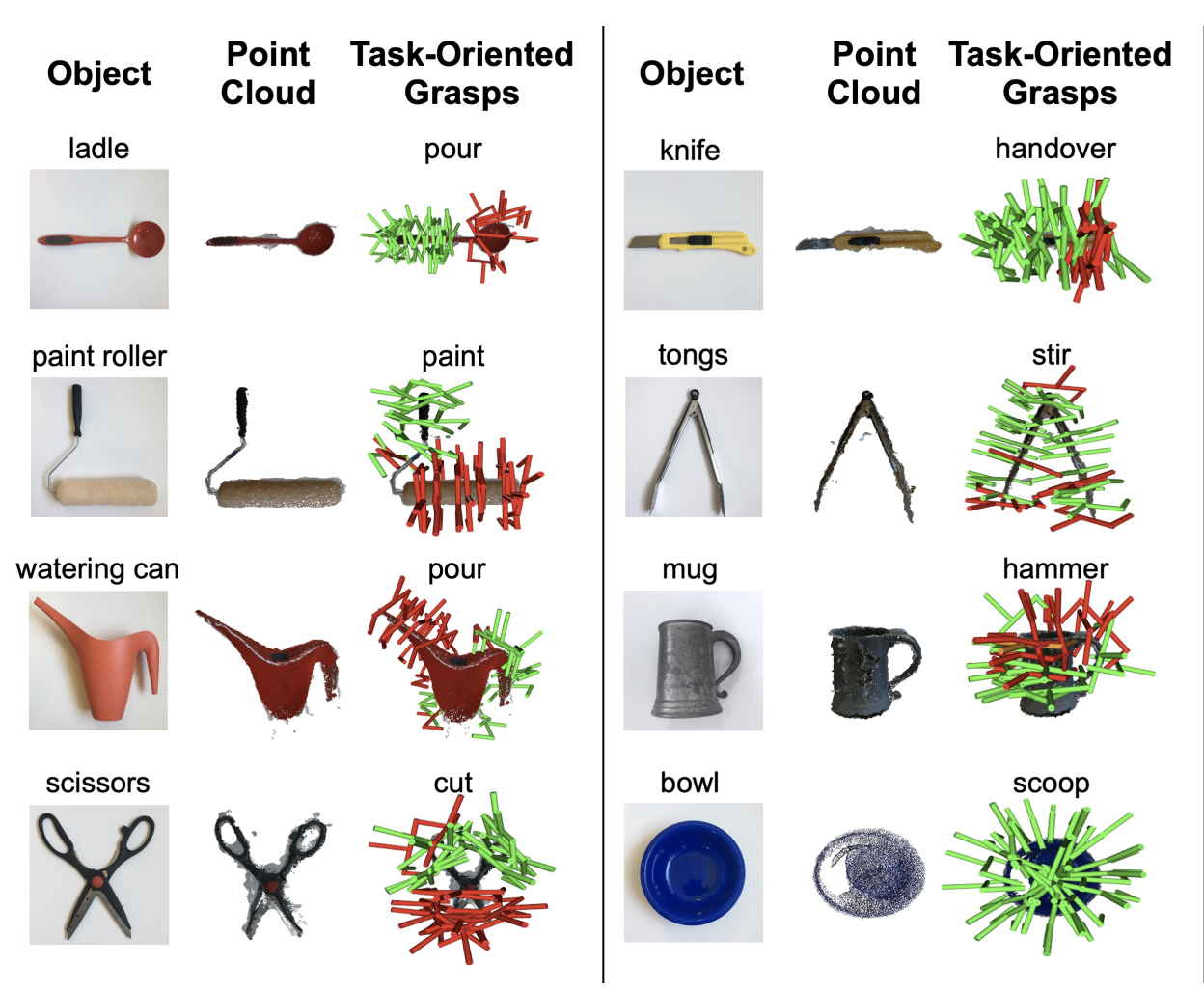
Same Object, Different Grasps: Data and Semantic Knowledge for Task-Oriented Grasping.
Adithya Murali, Wei Liu, Kenneth Marino, Sonia Chernova, Abhinav Gupta
CoRL 2020
A new dataset for semantic grasping and knowledge-graph based method.
[Paper]

Empirically Verifying Hypotheses Using Reinforcement Learning.
Kenneth Marino, Rob Fergus, Arthur Szlam, Abhinav Gupta
Under Review
[Paper]

OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge.
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, Roozbeh Mottaghi
CVPR 2019
OK-VQA is a new dataset for visual question answering that requires methods which can draw upon outside knowledge to answer questions.
[Paper] [Website]

Hierarchical RL Using an Ensemble of Proprioceptive Periodic Policies.
Kenneth Marino, Abhinav Gupta, Rob Fergus, Arthur Szlam
ICLR 2019
We introduce a simple, robust approach to hierarchically training an agent in the setting of sparse reward tasks taking inspiration from ideas of periodicity and proprioception.
[Paper] [Website] [Code]

The Pose Knows: Video Forecasting by Generating Pose Futures.
Jacob Walker, Kenneth Marino, Abhinav Gupta, Martial Hebert
ICCV 2017
We introduce a new method for video forecasting that exploits human pose detectors as a free source of supervision to break the forecasting problem into a high-level pose prediction and then a low-level video stream prediction.
[Paper] [Website] [Code]
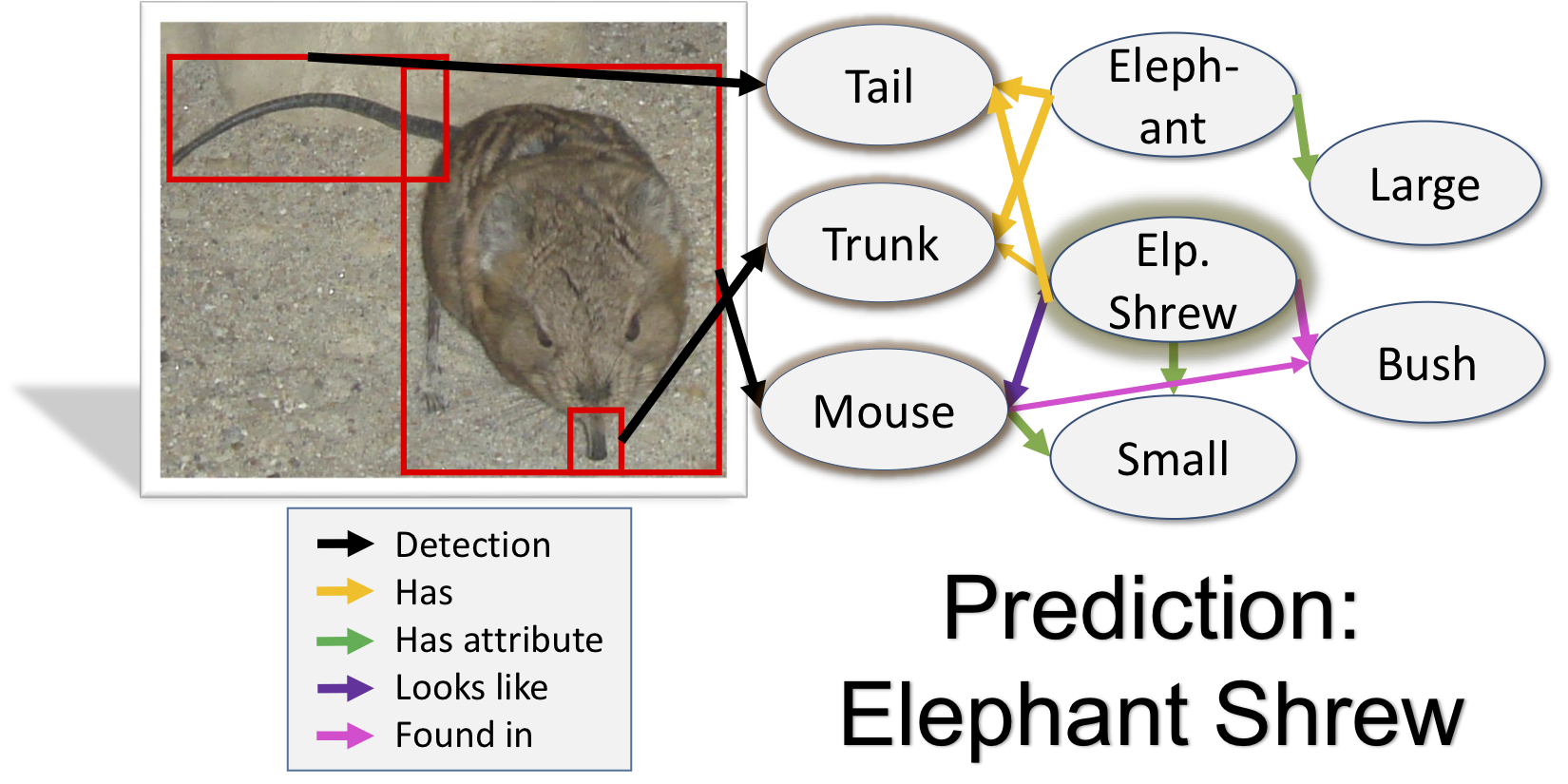
The More You Know: Using Knowledge Graphs for Image Classification.
Kenneth Marino, Ruslan Salakhutdinov, Abhinav Gupta
CVPR 2017
We introduce the Graph Search Neural Network as a way of efficiently incorporating large knowledge graphs into an end-to-end vision classification pipeline.
[Paper] [Code]